安装 monitedge
monitedge 需要部署在用户私有网络内,负责从 SaaS 同步告警规则,周期性查询数据源并进行阈值判定,产生告警事件并推送给 SaaS 端。
菜单入口:告警引擎 → 引擎安装/升级
支持 Linux、Docker、Kubernetes 三种安装方式。
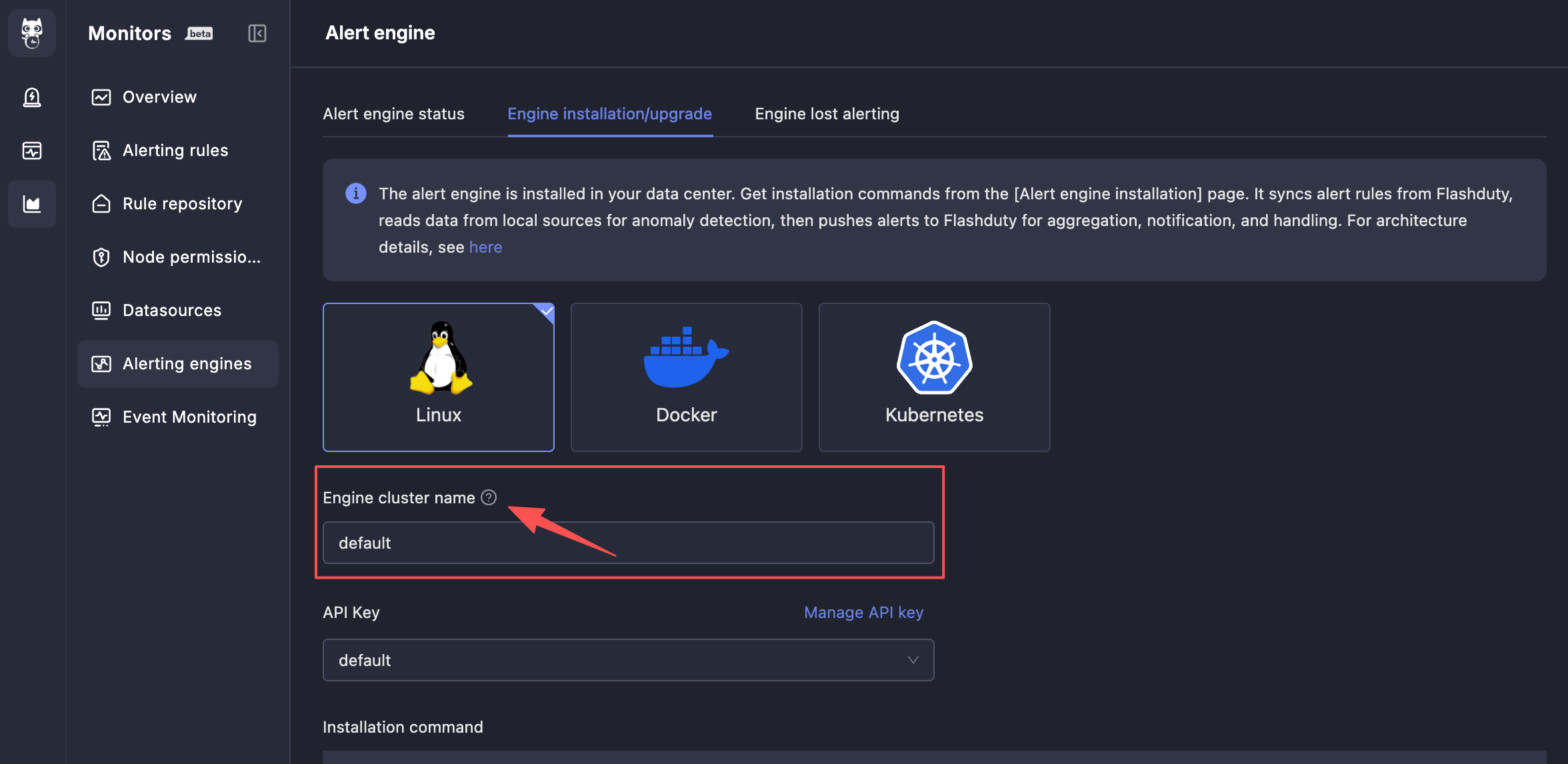
告警引擎状态
monitedge 安装完成后,会自动连接 SaaS 端并周期性同步告警规则。您可以在告警引擎状态页面查看当前状态信息。
长期没有心跳的引擎实例会展示删除按钮,可点击移除以避免引擎失联告警。
引擎失联告警
monitedge 挂掉影响很大,因此提供引擎失联告警。
多个实例组成的引擎集群,只要集群中有一个实例存活,就不会触发引擎失联告警。
创建数据源
菜单入口:数据源 → 新建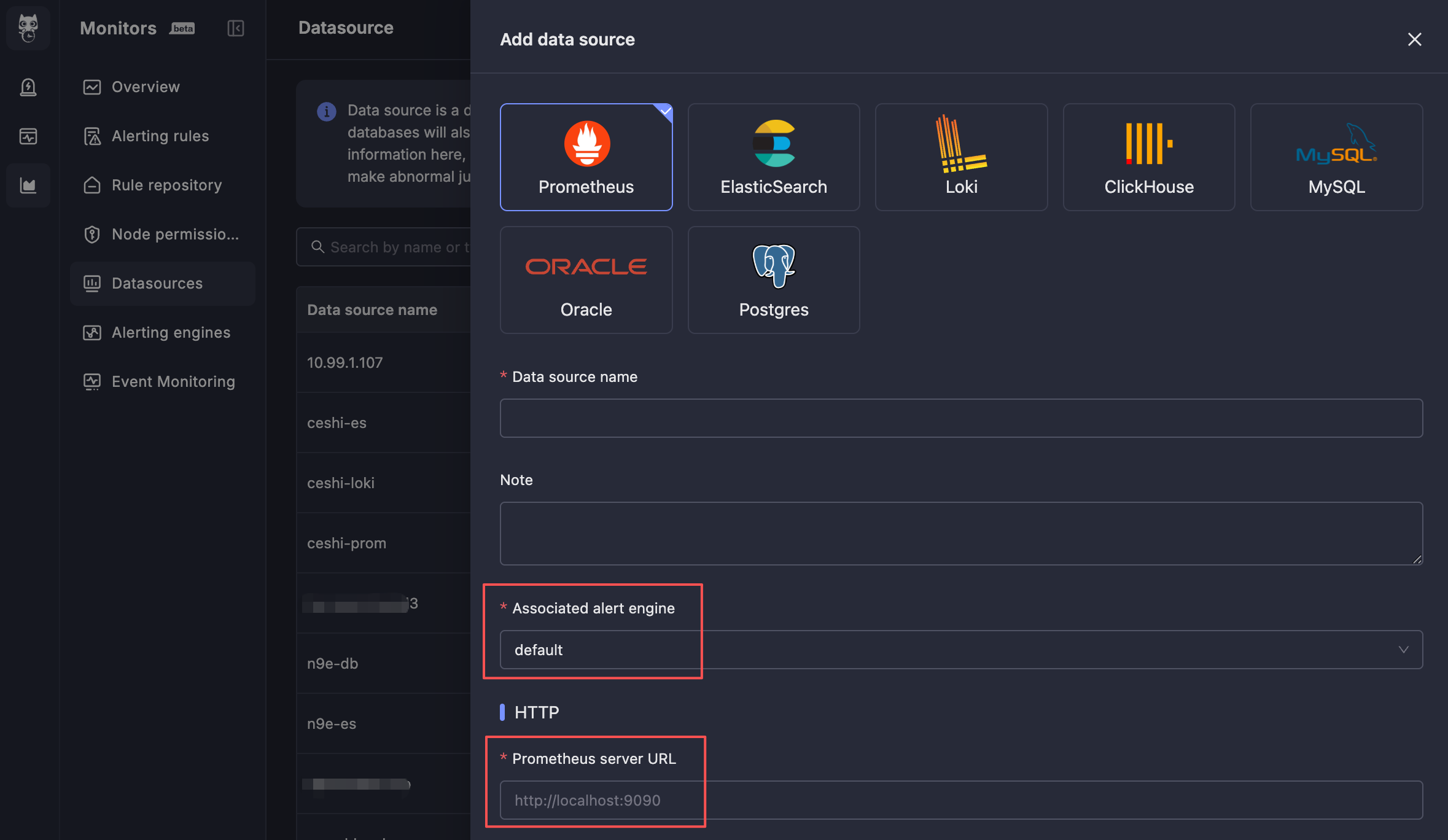
| 配置项 | 说明 |
|---|---|
| 关联告警引擎 | 指定该数据源由哪个告警引擎集群进行数据查询和告警判定,通常选择同机房的集群 |
| 数据源连接地址 | 给 monitedge 连接的地址,必须是 monitedge 能访问到的内网地址 |
创建告警规则
菜单入口:告警规则 告警规则可能会很多,Monitors 提供树形分组结构进行分类管理。每个告警规则都要属于某个分组,您可以先创建分组,再在分组下创建告警规则。基础配置
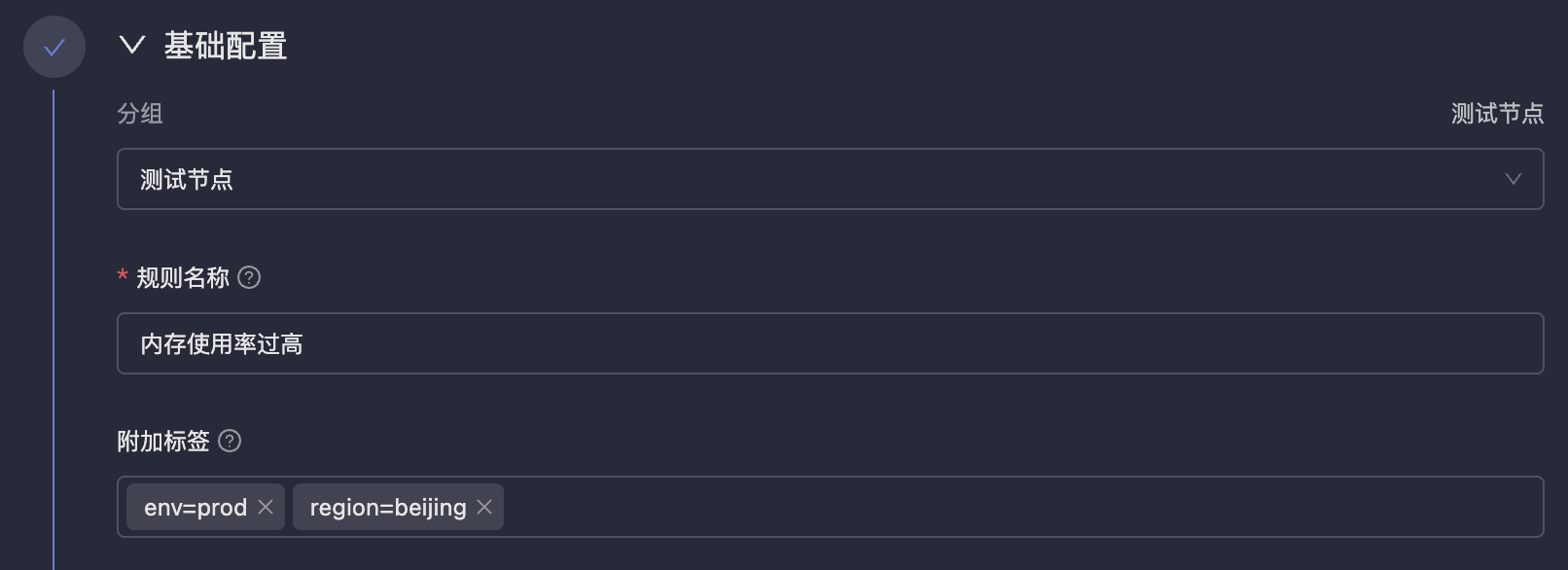
| 配置项 | 说明 |
|---|---|
| 规则名称 | 告警规则的名称,不支持引用变量(固定名称便于过滤、聚合操作) |
| 附加标签 | 类似 Prometheus 中的 labels,会附加到所有告警事件上,便于过滤、路由、抑制 |
数据源选择
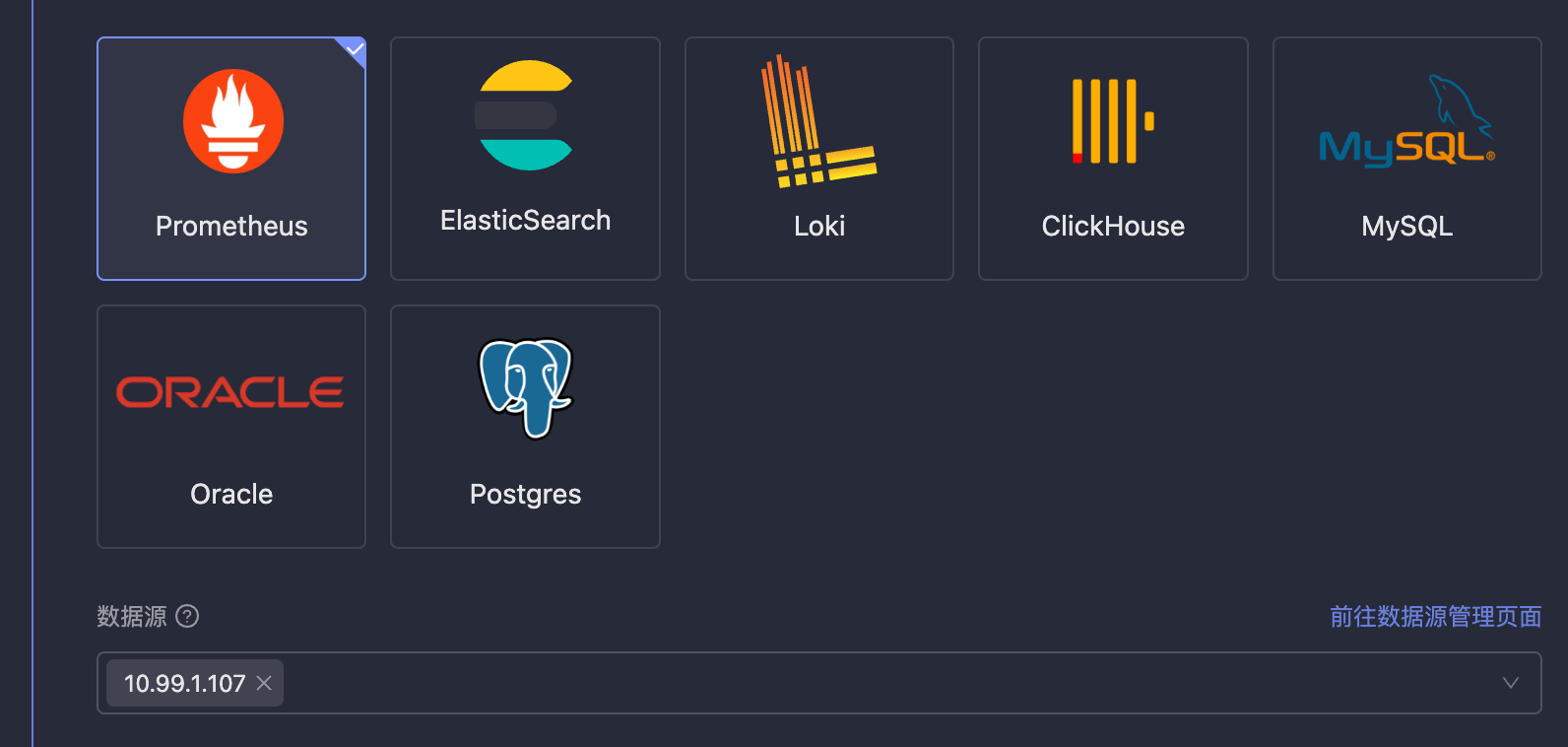 Monitors 支持一个规则生效到多个数据源,提供两种绑定方式:
Monitors 支持一个规则生效到多个数据源,提供两种绑定方式:
- 名称通配:通过通配符匹配数据源名称。
*匹配所有数据源,db-*匹配所有以db-开头的数据源。存储的是名称字符串,数据源改名会影响匹配。 - 精确匹配:从下拉列表中按 ID 选择具体数据源,不受数据源改名影响。
查询检测方式
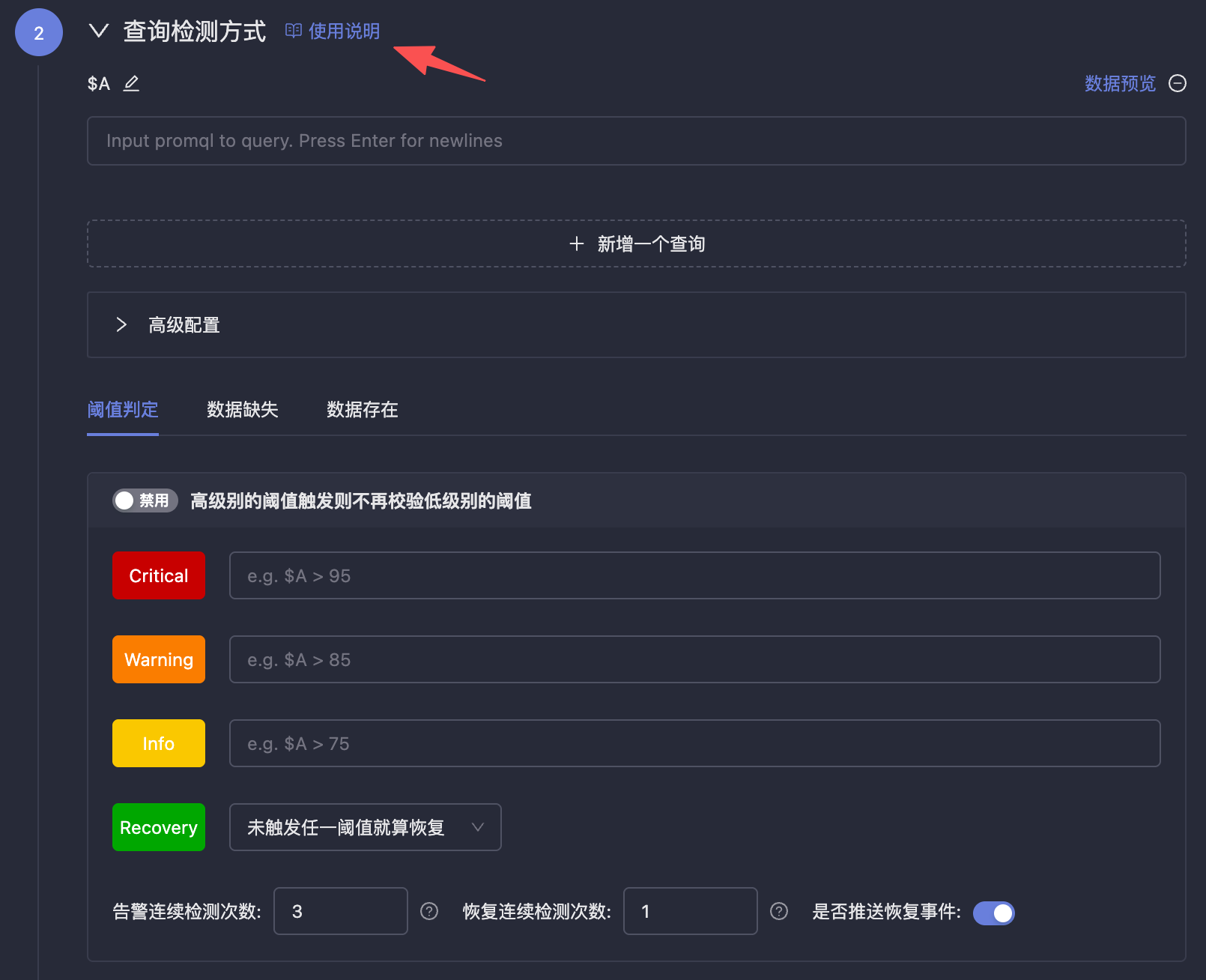 配置如何查询数据源及如何判定告警条件。请阅读页面上 查询检测方式 右侧的使用说明。
配置如何查询数据源及如何判定告警条件。请阅读页面上 查询检测方式 右侧的使用说明。
| 配置项 | 说明 |
|---|---|
| 查询偏移 | 设置查询时间偏移量(秒),用于处理数据源存在采集延迟的场景。例如设置为 60,则查询窗口整体向前偏移 60 秒,确保数据已完成写入后再查询 |
检测频率与生效时间
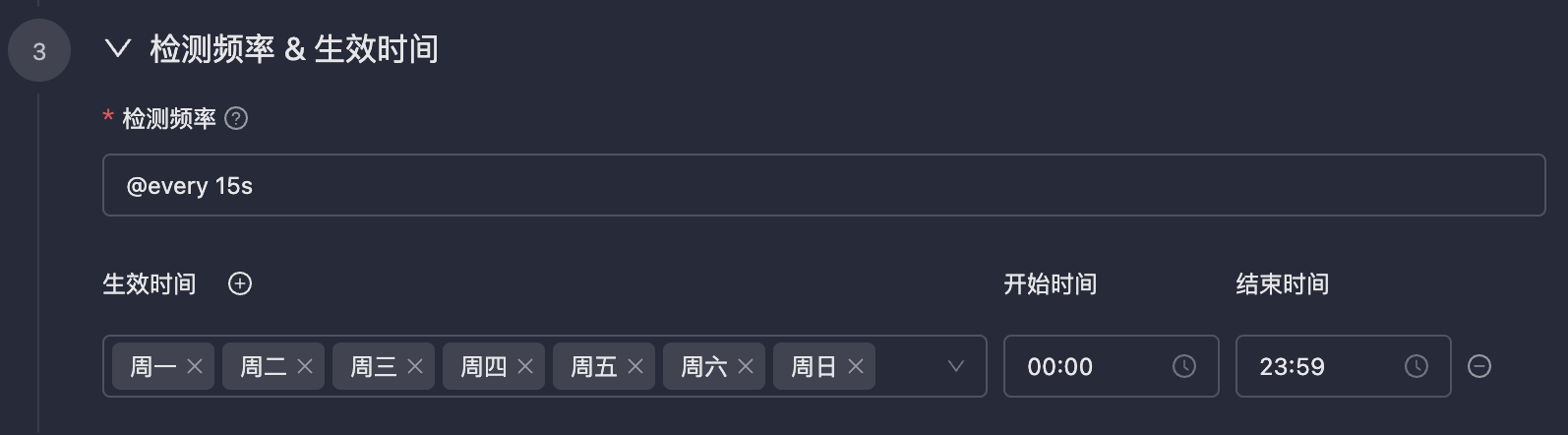
| 配置项 | 说明 |
|---|---|
| 检测频率 | 通常是周期性检测,也支持 cron 表达式(精确到秒) |
| 生效时间 | 告警规则的生效时间段,非生效时间段内不会触发告警 |
事件配置
| 配置项 | 说明 |
|---|---|
| 自定义字段 | 类似 Prometheus 中的 annotations,可附加仪表盘 URL、SOP URL 等 |
| 关联查询 | 不作为阈值判定依据,但可放到备注中作为变量引用(如附加日志样例) |
| 备注描述 | 非结构化文本字段,支持引用变量,便于值班人员快速定位问题 |
| 协作空间 | 指定 Flashduty On-call 中的协作空间,不指定则根据集成路由规则投递 |
| 重复通知 | 告警未恢复时持续通知,可配置间隔和最大次数(默认 10000 次) |
最大通知次数并不代表终端用户收到的消息提醒次数。因为 Monitors 产生的告警事件会投递到 On-call,可能会被聚合降噪,最终发送次数取决于 On-call 配置。
查看效果
完成配置后,如果告警条件触发,告警规则前的状态会变成Triggered。
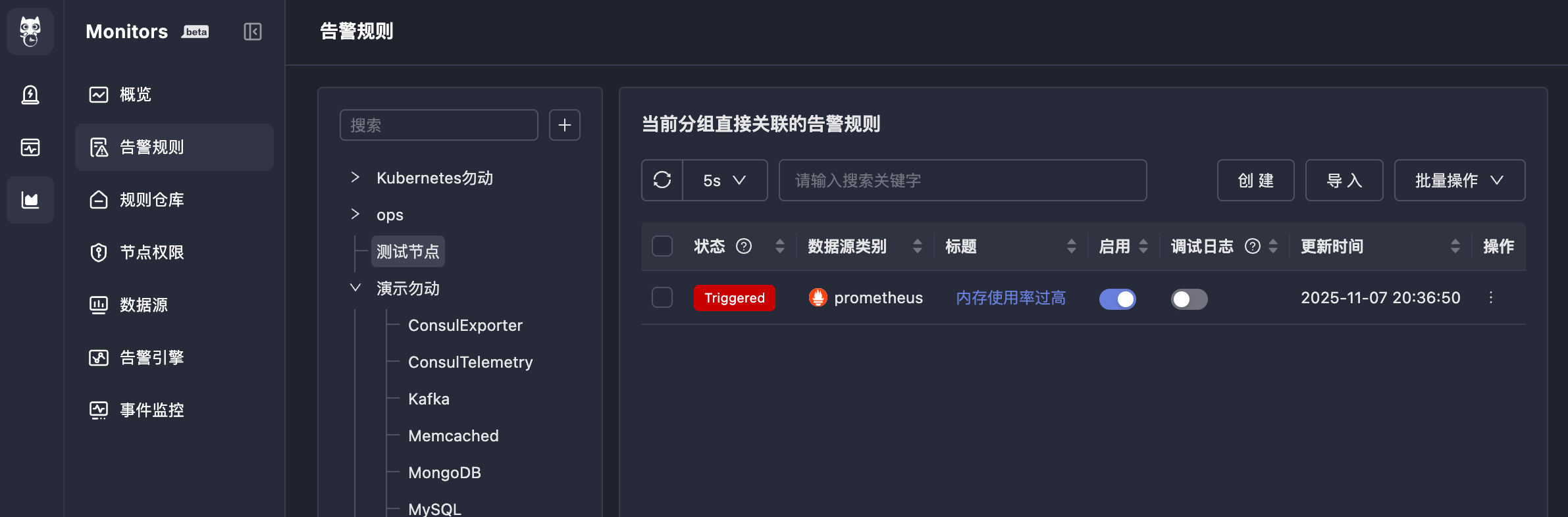 点击
点击 Triggered 可以看到该规则产生的告警事件(也可到 On-call 中查看):
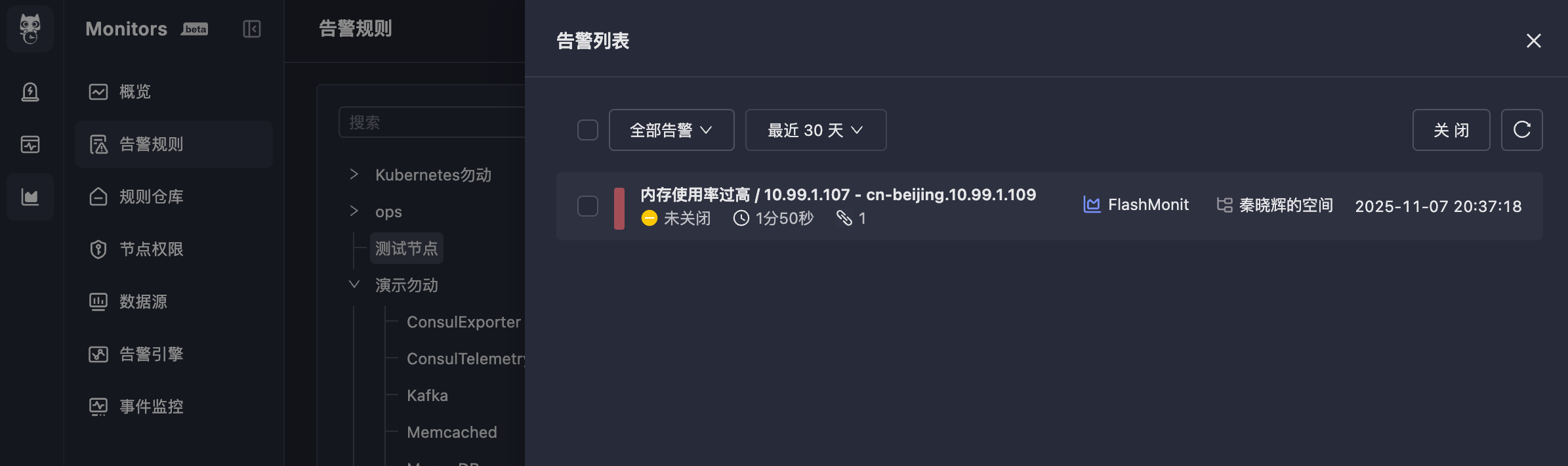 点击告警事件标题,可查看详情,分为三个标签页:告警概览、时间线、关联事件。
点击告警事件标题,可查看详情,分为三个标签页:告警概览、时间线、关联事件。
批量操作
告警规则列表支持多选后进行批量操作,提升规则管理效率。批量启用/禁用/删除
在列表中勾选多条规则后,可以一键批量启用、批量禁用或批量删除。批量编辑字段
勾选多条规则后点击批量更新,可以统一修改以下 9 个字段:| 可批量编辑的字段 | 说明 |
|---|---|
| 附加标签 | 统一设置 labels |
| 数据源 | 统一切换数据源 |
| 检测频率 | 统一调整检测周期 |
| 生效时间 | 统一配置生效时间段 |
| 查询延迟 | 统一设置查询延迟时间 |
| 自定义字段 | 统一配置 annotations |
| 协作空间 | 统一指定告警投递的协作空间 |
| 重复发送配置 | 统一设置重复通知间隔和次数 |
| 调试日志 | 统一开启或关闭调试日志 |
批量移动
勾选多条规则后,可以将它们批量移动到其他文件夹中。导入告警规则
Monitors 支持三种导入模式,你可以根据来源选择最合适的方式。 菜单入口:告警规则 → 导入从规则库导入
选择规则库模式,可以从规则库中选择已有的规则模板进行导入。导入时需要指定告警事件投递的协作空间。从 JSON 导入
选择 Flashduty Rules JSON 模式,粘贴 JSON 格式的告警规则数组。该格式与导出功能产生的 JSON 格式一致,适合跨租户或跨环境迁移告警规则。导入时需要指定协作空间。JSON 内容必须是数组格式(以
[ 开头),每个元素是一条完整的告警规则定义。从 Prometheus YAML 导入
选择 Prometheus Rules YAML 模式,粘贴标准的 Prometheus 告警规则 YAML 内容。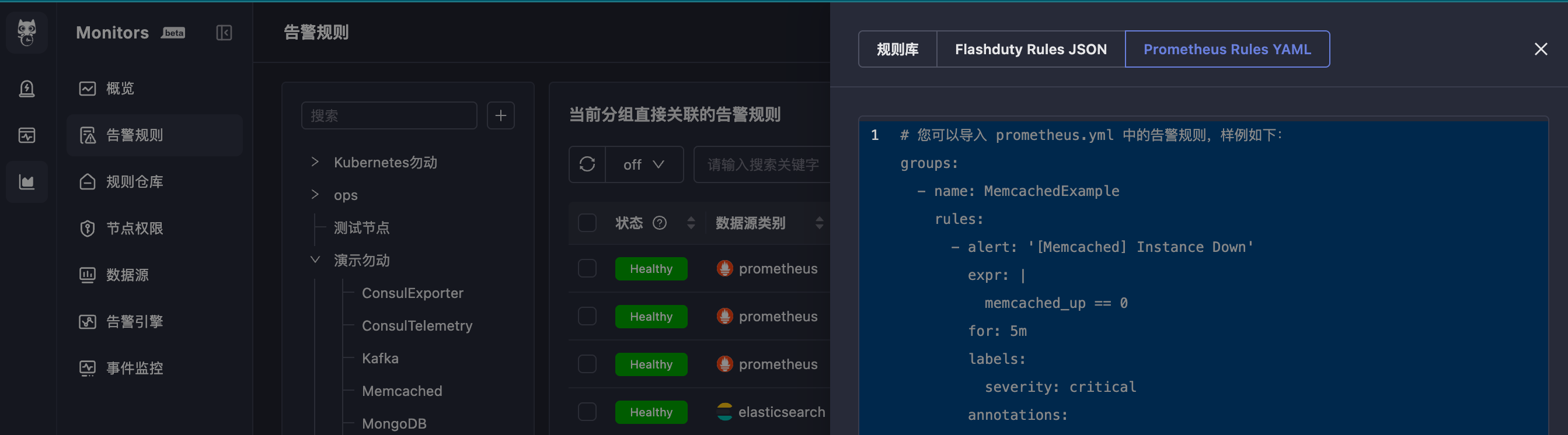
要求以
groups 为根节点的标准格式。YAML 缩进必须正确,否则会导入失败。每条规则需要包含 alert 和 expr 字段。导入结果
如果部分规则导入失败,系统会弹出导入结果表格,展示每条规则的导入状态和错误信息。全部成功时直接提示导入成功。导出告警规则
在列表中勾选需要导出的规则,点击导出按钮。系统以 JSON 格式展示所选规则的完整配置,你可以:- 下载:将 JSON 保存为
monit.json文件 - 复制:将 JSON 内容复制到剪贴板
规则变更记录
每条告警规则都有完整的变更审计记录。你可以在规则详情中查看变更记录,了解规则的历史修改情况。查看变更记录
变更记录列表展示每次操作的以下信息:| 列信息 | 说明 |
|---|---|
| 操作时间 | 变更发生的时间 |
| 操作类型 | 如创建、更新等 |
| 操作人 | 执行变更的用户 |