
快速开始
monitedge、创建数据源、创建告警规则。一、安装 monitedge
monitedge 需要部署在用户私有网络内,负责从 SaaS 同步告警规则,周期性查询数据源并进行阈值判定,产生告警事件并推送给 SaaS 端。要体验告警功能,必须先安装 monitedge。monitedge 会组成一个集群,共同分片处理告警规则,避免单点故障风险。如果只规划一套 monitedge 集群,引擎集群名字可以维持默认的 default;如果规划多套 monitedge 集群,比如美东机房一套,华南机房一套,请为每套集群指定不同的引擎集群名字。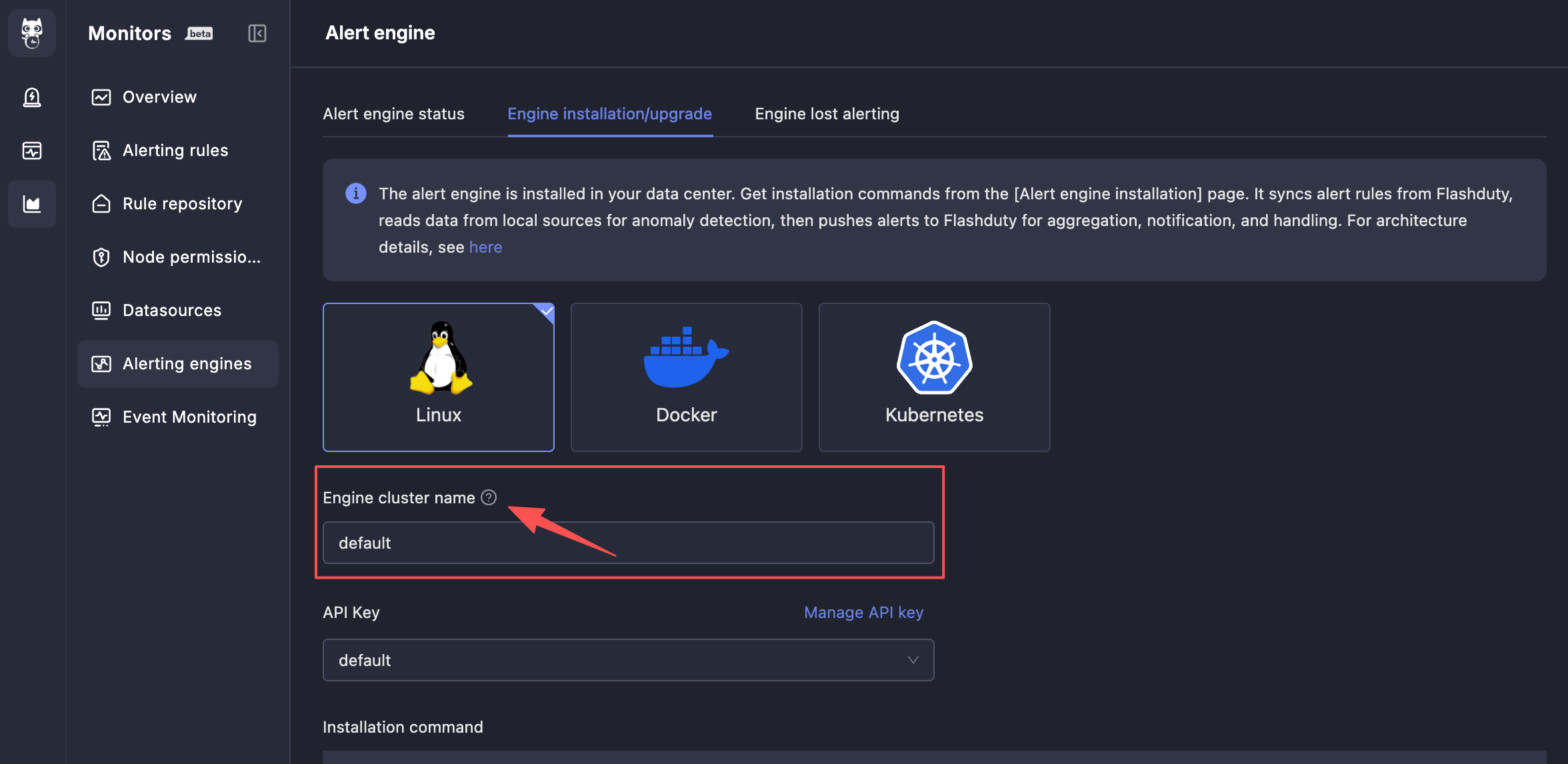
告警引擎状态
monitedge 安装完成后,会自动连接 SaaS 端并周期性同步告警规则,您可以在告警引擎状态页面查看当前告警引擎的状态信息。引擎失联告警
monitedge)如果挂掉了,影响很大,因此提供引擎失联告警,在引擎挂掉时及时发出告警通知。多个实例组成的引擎集群,只要集群中有一个实例存活,就不会触发引擎失联告警,因为集群还可以正常工作。二、创建数据源
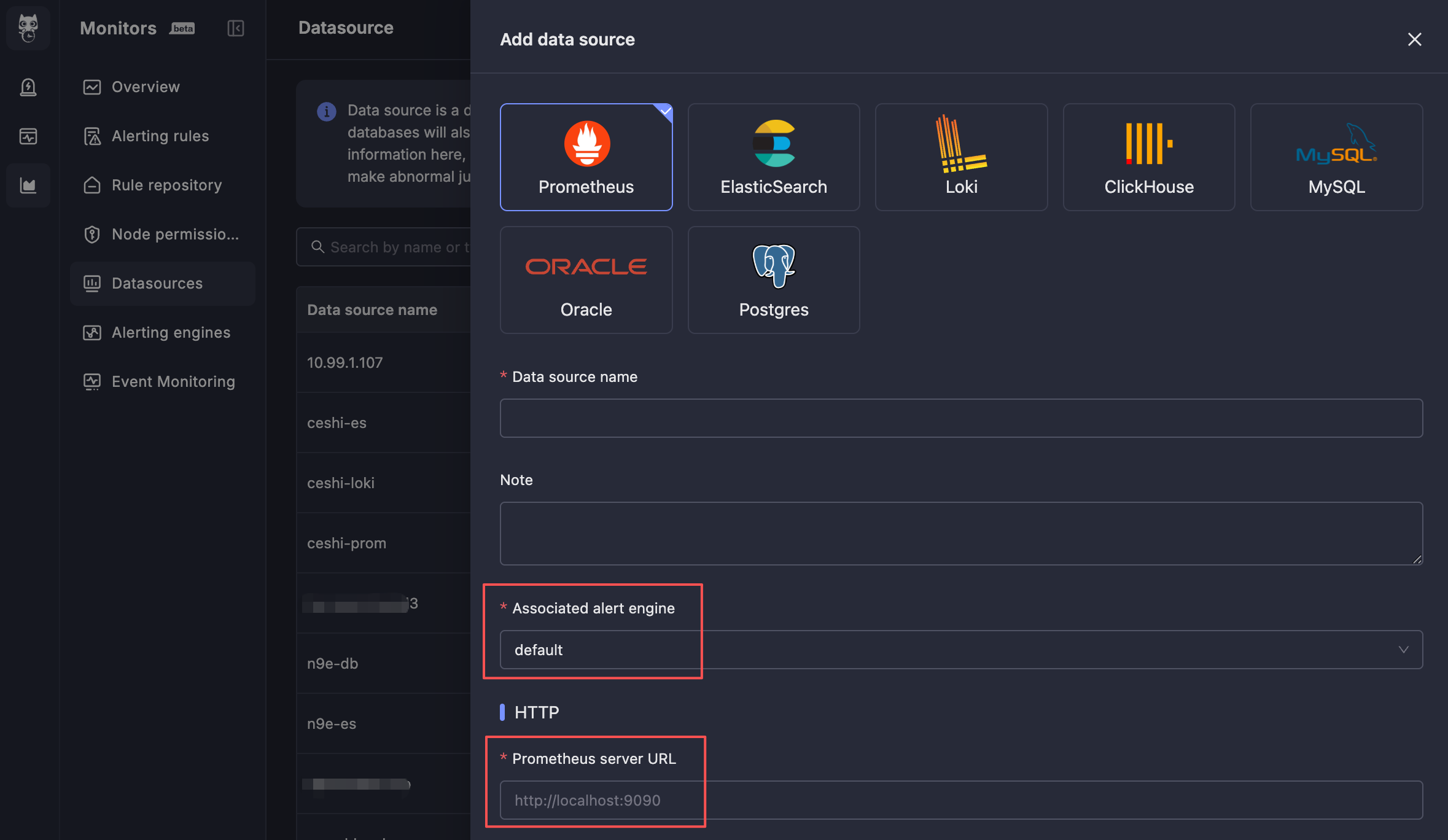
monitedge 连接的地址,必须是 monitedge 能访问到的地址。通常是一个内网地址。三、创建告警规则
基础配置
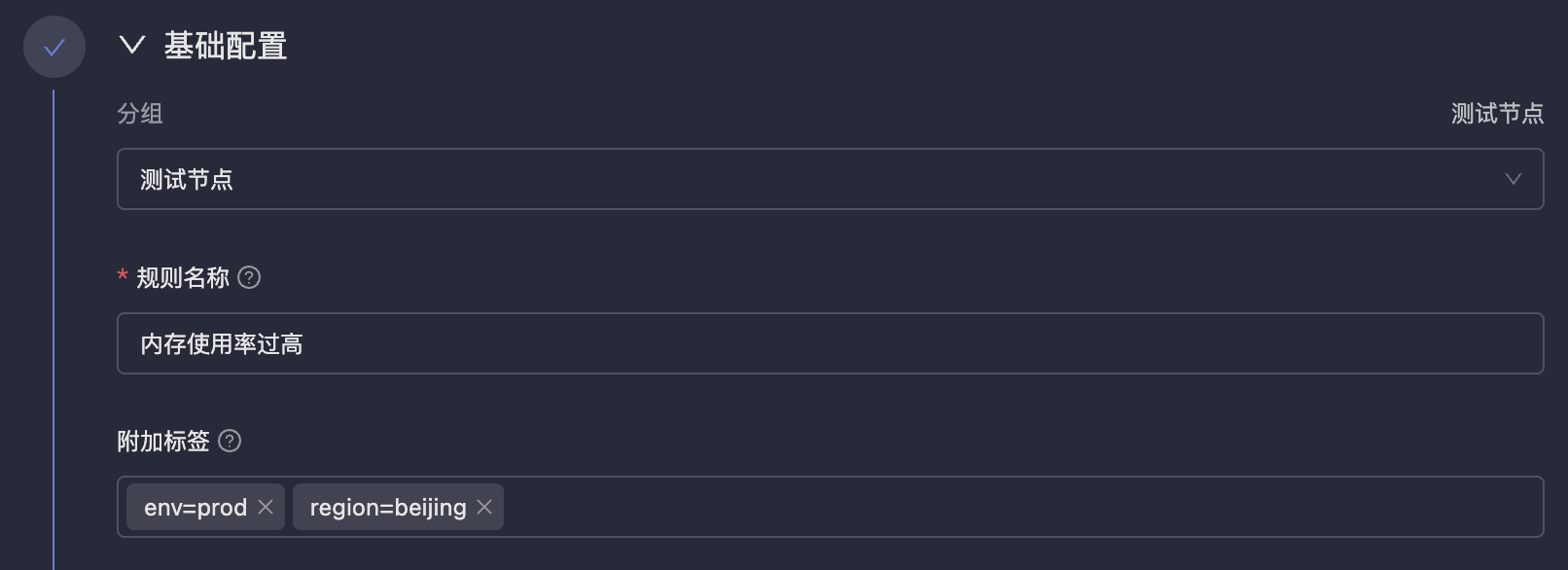
labels,会附加到该规则产生的所有告警事件上,便于在 On-call 中进行过滤、路由、抑制等操作。数据源选择
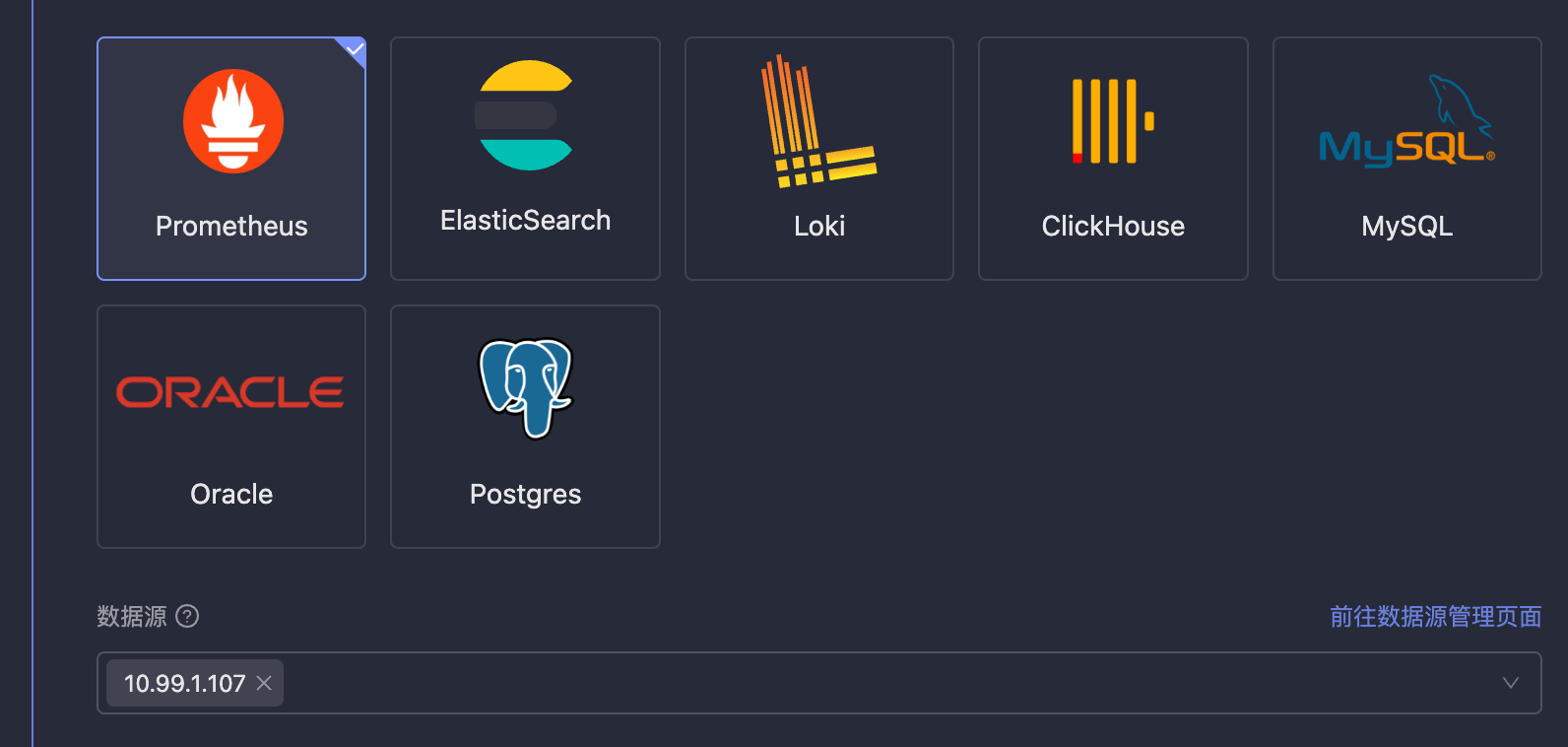
db-*,表示该规则会作用到所有名称以 db- 开头的数据源上。⚠️ 注意:数据源这里因为要支持通配符,所以存储的是数据源名称,而不是数据源 ID。��如果数据源名称修改了,会影响告警规则的生效,请谨慎修改数据源名称。
查询检测方式
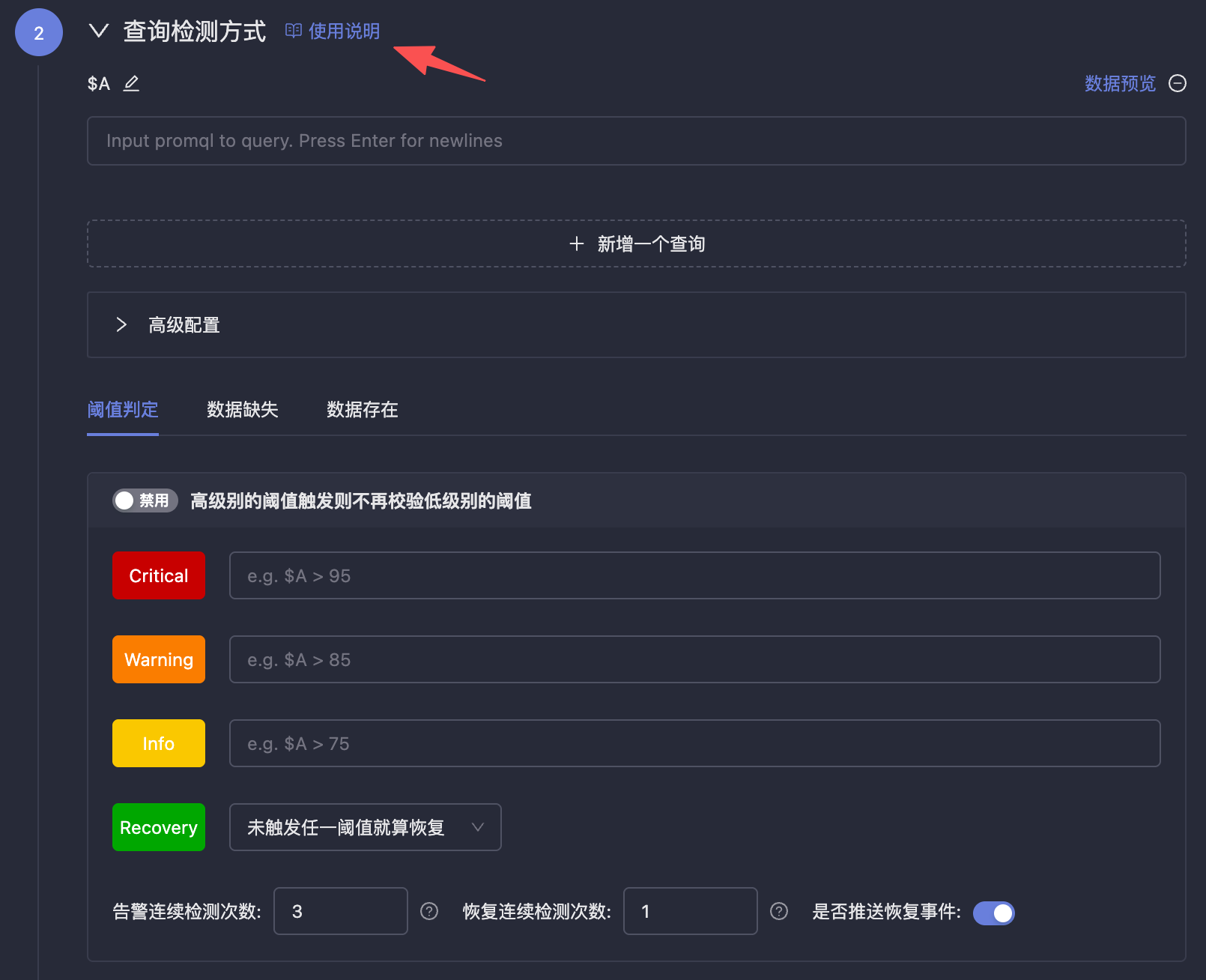
检测频率 & 生效时间
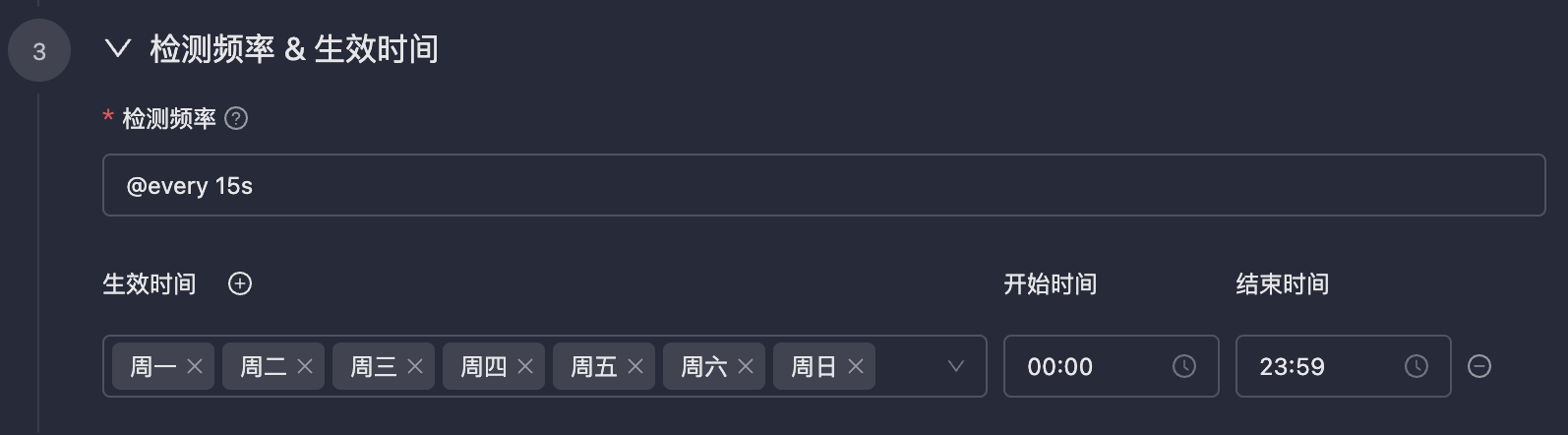
cron 表达式。Monitors 中的 cron 表达式精确到秒。事件配置
annotations,会附加到该规则产生的所有告警事件上,比如附加仪表盘的 URL、SOP 的 URL 等。⚠️ 注意:最大通知次数,并不表示终端用户收到的消息提醒次数。因为 Monitors 产生的告警事件会投递到 On-call,On-call 可能会对告警事件做聚合降噪处理,最终发送给终端用户的消息提醒次数,取决于 On-call 的配置。
四、效果
Triggered。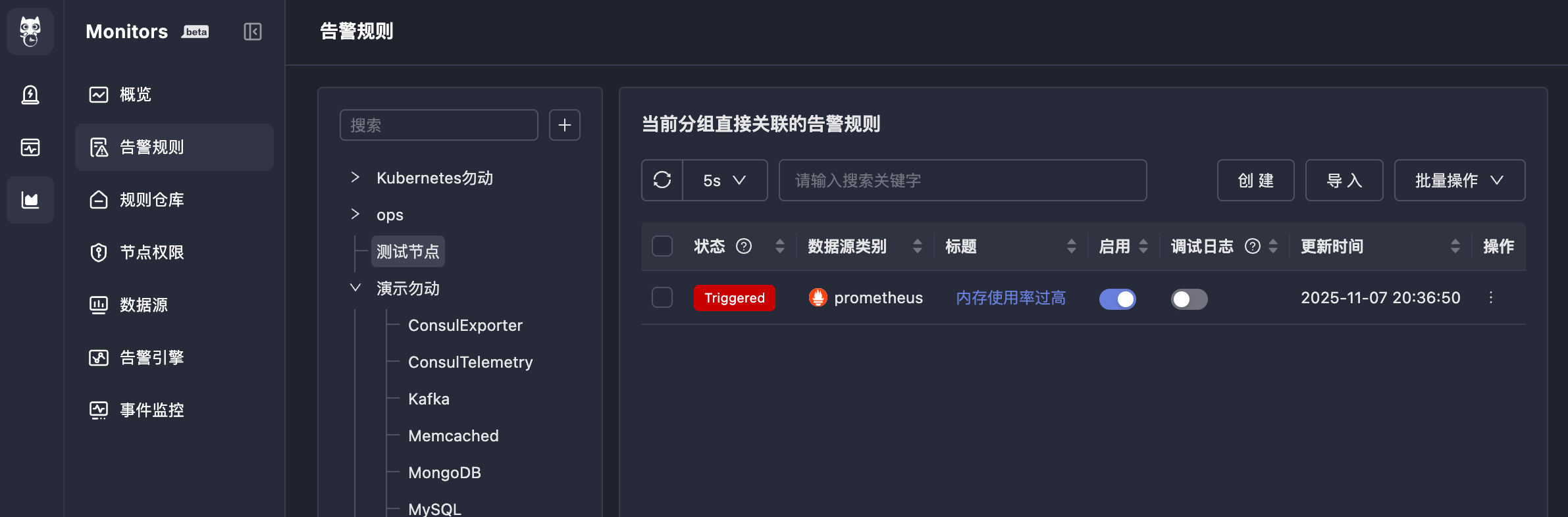
Triggered 会看到这个规则产生的告警事件(您也可以到 On-call 中查看):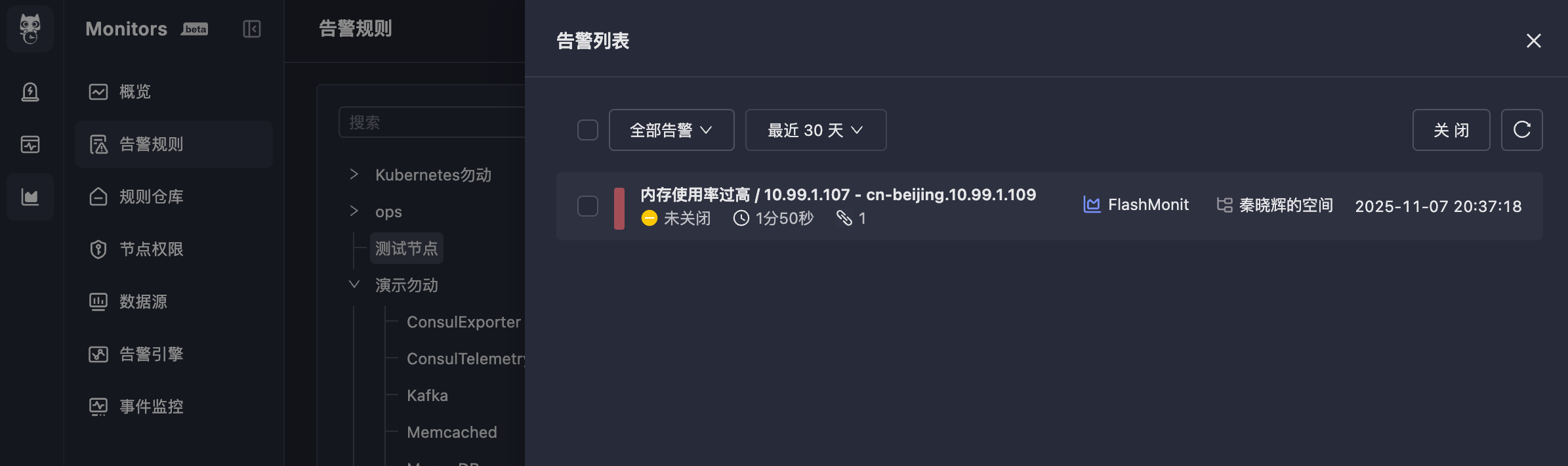
五、导入告警规则
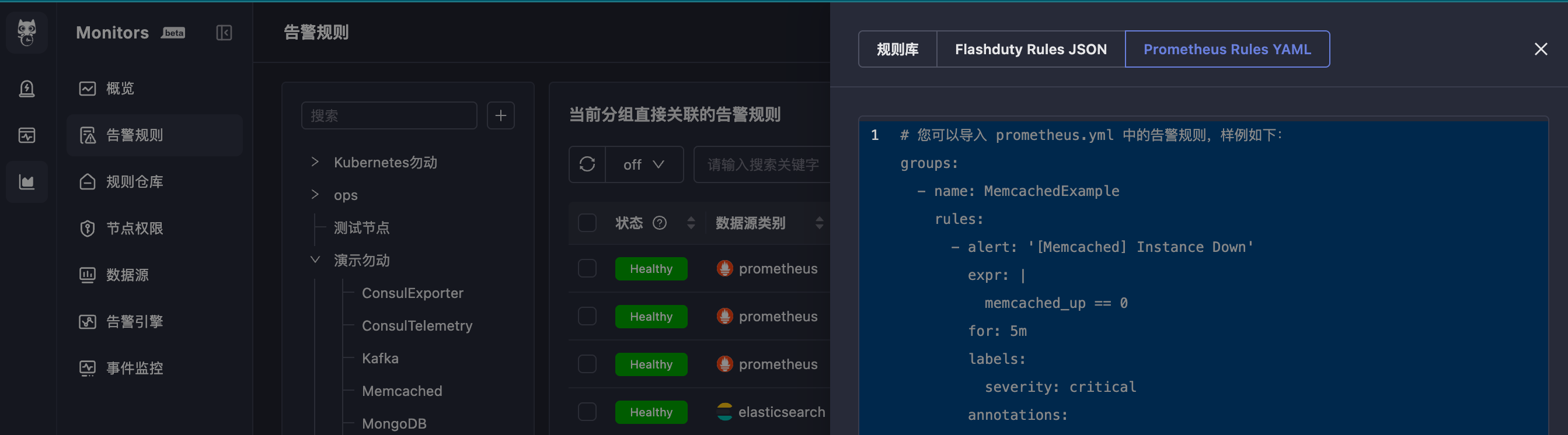
groups 为根节点的标准 Prometheus 告警规则文件格式。YAML 的缩进必须正确,否则会导入失败。

 微信扫码交流
微信扫码交流修改于 2025-11-08 06:21:29